Lugha-Llama: Adapting Large Language Models for African Languages

Lugha-Llama: Adapting Large Language Models for African Languages
This blog post introduces Lugha-Llama, a new family of large language models (LLMs) specifically adapted for African languages. The primary motivation behind this project is the significant underrepresentation of low-resource African languages in the training datasets of existing LLMs, which leads to poor performance and understanding of these languages.
The Challenge of Underrepresentation
Large language models have demonstrated remarkable capabilities, but their effectiveness is heavily dependent on the quantity and quality of training data. Unfortunately, many African languages, particularly those with fewer digital resources, are largely absent from the massive datasets used to train models like Llama-3.1. This data imbalance results in LLMs struggling to comprehend, generate, or process text in these languages.
Introducing Lugha-Llama Models
To address this gap, the Princeton Laboratory for Artificial Intelligence Research has released three Lugha-Llama models. These models are based on Meta's Llama-3.1-8B architecture and have been fine-tuned using a curated dataset of African languages. The name "Lugha" is derived from the Kiswahili word for "language."
These Lugha-Llama models have achieved state-of-the-art performance among open-source models on challenging benchmarks for African languages, including IrokoBench and AfriQA.
All Lugha-Llama models are publicly available on the Hugging Face Hub.
Training Data: The WURA Corpus
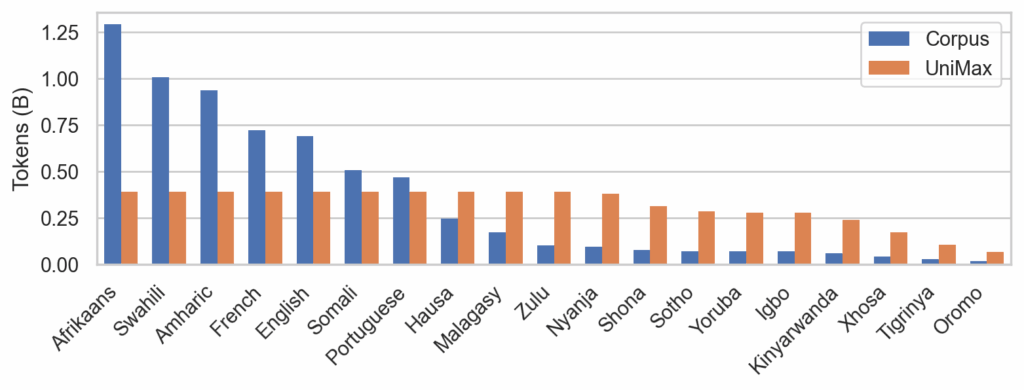
A key component of this project is the WURA corpus, an openly available multilingual dataset comprising sixteen African languages and four high-resource languages commonly spoken on the African continent. This corpus was created by carefully inspecting and cleaning data from mC4 and by crawling African websites. It also includes languages with non-Latin scripts, such as Amharic, Arabic, and Tigirinya.
Addressing Data Imbalance with UniMax Sampling
Training on imbalanced multilingual corpora presents a challenge: avoiding overfitting and memorization of high-resource languages. To mitigate this, the researchers employed UniMax sampling. This technique aims to sample data as uniformly as possible across languages while controlling the repetition of any single language's data. Rare languages were up-sampled by up to four epochs, a strategy found to cause no discernible degradation during model training.
The figure below illustrates the token distribution per language in the training corpus and the sampling proportions using UniMax sampling:
Incorporating English Data for Continued Pre-training
To prevent catastrophic forgetting of the base Llama-3.1-8B model's capabilities, English data was retained in the continued pre-training mix. Two sources of English data were experimented with:
- FineWeb-Edu: High-quality, knowledge-rich educational documents.
- OpenWebMath: A curated dataset of mathematical documents.
Experiments combined 40% English data with 60% WURA data. This "replay" strategy has proven effective in preventing catastrophic forgetting during continued pre-training.
The Lugha-Llama Model Variants
The project released three distinct Lugha-Llama models, all based on an 8 billion parameter model trained on 10 billion tokens:
- Lugha-Llama-8B-wura: Trained exclusively on the WURA corpus, maximizing African language data.
- Lugha-Llama-8B-wura_edu: Trained on a mix of WURA data and educational English documents from FineWeb-Edu.
- Lugha-Llama-8B-wura_math: Trained on a mix of WURA data and English mathematical data from OpenWebMath.
All models were trained with a batch size of 4 million tokens and a maximum sequence length of 8,192 tokens for 2,400 steps.
Evaluation and Performance
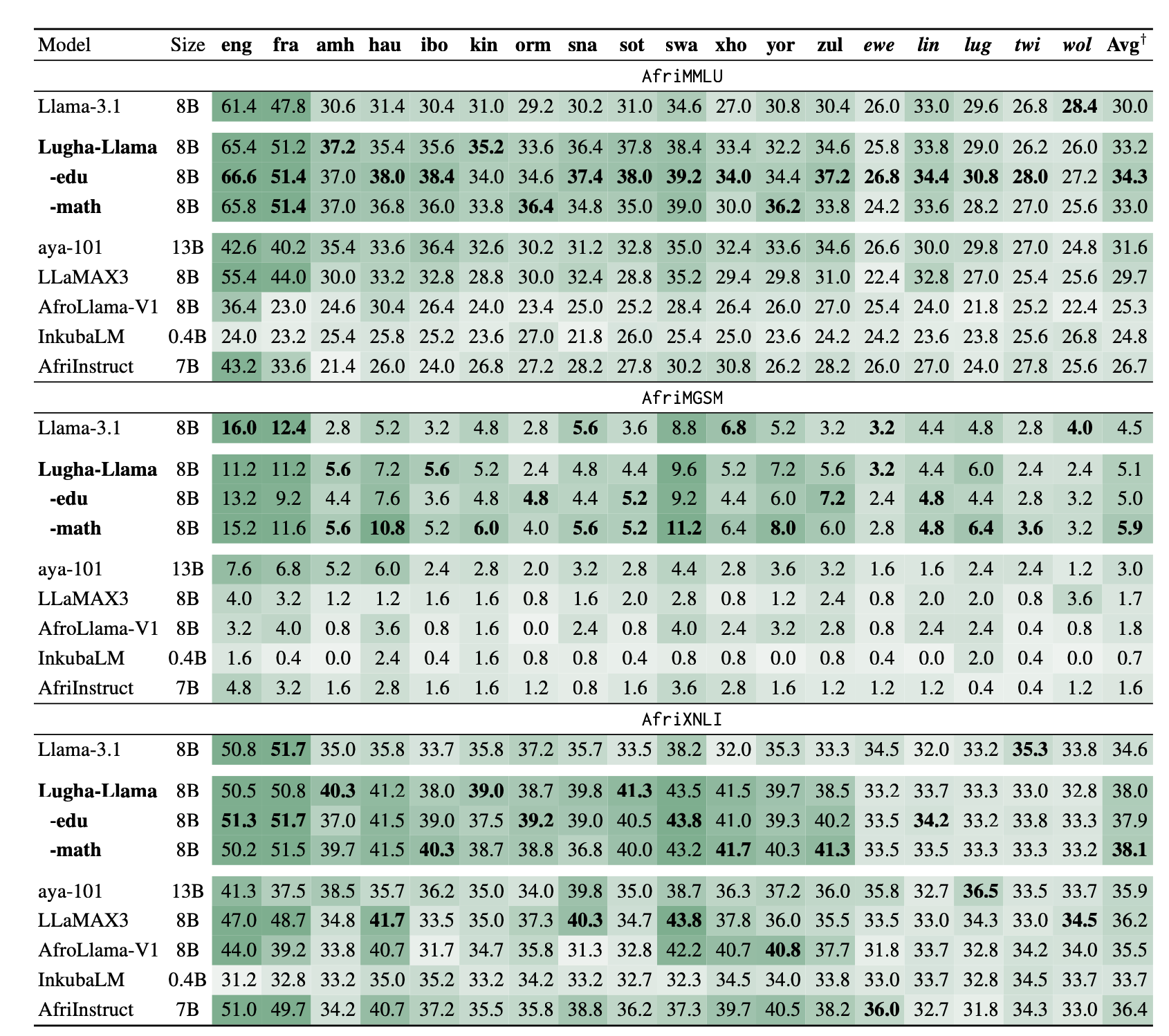
Model evaluation was conducted using the LM Evaluation Harness on the AfriQA dataset and three tasks from IrokoBench: AfriMMLU (knowledge-based QA), AfriMGSM (mathematical reasoning), and AfriXNLI (natural language inference).
Key findings from the evaluation include:
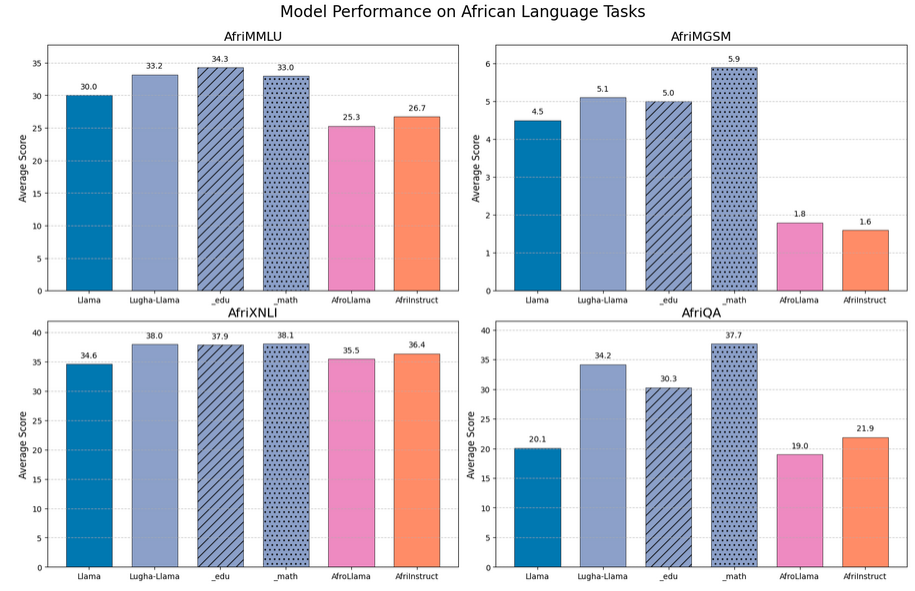
- All three Lugha-Llama models consistently outperformed similarly sized baselines across AfriMMLU, AfriMGSM, AfriXNLI, and AfriQA.
- Including FineWeb-Edu data (
_edu) improved performance across languages in AfriMMLU, while OpenWebMath data (_math) enhanced performance in AfriMGSM, indicating positive cross-lingual transfer of skills and knowledge.
The detailed comparison table shows Lugha-Llama models outperforming baselines, with significant improvements in languages like Igbo (ibo) for AfriMMLU.
Conclusion and Future Directions
Lugha-Llama represents a significant advancement in making LLMs more inclusive and effective for African languages. By leveraging continued pre-training with curated African language data and high-quality English datasets, these models achieve state-of-the-art results. This work contributes to the vision of greater representation for African languages in AI research and development.
Future research directions include exploring linguistic transfer mechanisms more deeply and investigating the impact of incorporating data from FineWeb2, which includes more non-English data, to achieve similar performance gains.
Citation
The authors encourage citing the blog post if the Lugha-Llama models are used. The citation provided is:
@article{buzaaba2025lugha,
title={Lugha-Llama: Adapting Large Language Models for African Languages},
author={Buzaaba, Happy and Wettig, Alexander and Adelani, David Ifeoluwa and Fellbaum, Christiane},
journal={arXiv preprint arXiv:2504.06536},
year={2025}
}
Original article available at: https://blog.ai.princeton.edu/tag/large-language-models/page/3/